Technology
YACY consists mainly of four parts: the p2p index exchange protocol, based on http; a spider/indexer; a caching http proxy which is not only a simple increase in value but also an informtaion provider for the indexing engine and the built-in database engine which makes installation and maintenance of yacy very easy.
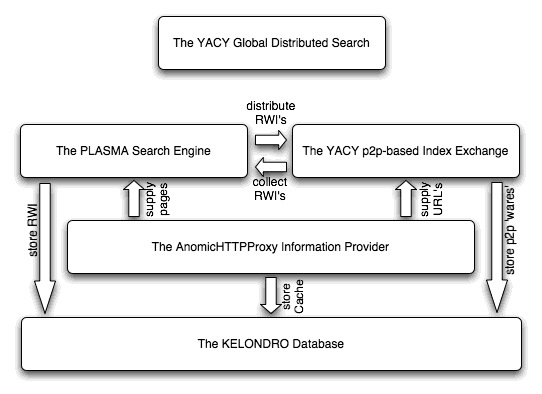
All parts of this architecture are included in the YACY distribution. The YACY search engine can be accessed through the built-in http server.
Algorithms
For our software architecture we emphasize that always the approriate data structure and algorithm is used
to ensure maximum performance. The right combination of structure and algorithm results in an ideal
order of computability which is the key to performant application design. We reject the myth that
the Java language is not appropriate for time-critical software; in contrast to that myth we
believe that Java with it's clean and save-to-use dynamic data structures is most notably qualified
to implement highly complex algorithms.
| Transparent HTTP and HTTPS Proxy and Caching: |
The proxy implementation provides a fast content-passing, since every file that the proxy reads from the targeted server is streamed directly to the accessing client while the stream is copied to a RAM cache for later processing. This ensures that the proxy mode is extremely fast and does not interrupt browsing. Whenever the Proxy idles, it processes it's RAM cache to perform indexing and storage to a local file of the cache. Every HTTP header that was passed along with the file is stored in a database and is re-used later on when a cache hit appears. The proxy function has maximum priority above other tasks, like cache management or indexing functions.
|
| Fast Database Implementation: |
We implemented a file-based AVL tree upon a random-access-file. Tree nodes can be dynamically allocated and de-allocated and an unused-node list is maintained. For the PLASMA search algorithm, an ordered access to search results are necessary, therefore we needed an indexing mechanism which stores the index in an ordered way. The database supports such access, and the resulting database tables are stored as a single file. The database does not need any set-up or maintenance tasks that must done by an administrator. It is completely self-organizing. The AVL property ensures maximum performance in terms of algorithmic order. Any database may grow to an unthinkable number of records: with one billion records a database request needs a theoretical maximum number of only 44 comparisments.
|
| Sophisticated Page Indexing: |
The page indexing is done by the creation of a 'reverse word index': every page is parsed, the words are extracted and for every word a database table is maintained. The database tables are held in a file-based hash-table, so accessing a word index is extremely fast, resulting in an extremely fast search. Conjunctions of search words are easily found, because the search results for each word is ordered and can be pairwise enumerated. In terms of computability: the order of the searched access efford to the word index for a single word is O(log <number of words in database>). It is always constant fast, since the data structure provides a 'pre-calculated' result. This means, the result speed is independent from the number of indexed pages! It only slows down for a page-ranking, and is multiplied by the number of words that are searched simultanously. That means, the search efford for n words is O(n * log w). You can't do better (consider that n is always small, since you rarely search for more that 10 words).
|
| Massive-Parallel Distributed Search Engine: |
This technology is the driving force behind the YACY implementation. A DHT (Distributed Hash Table) - like technique will be used to publish the word cache. The idea is, that word indexes travel along the peers before a search request arrives at a specific word index. A search for a specific word would be performed by computing the peer and point directly to the peer, that hosts the index. No peer-hopping or such, since search requests are time-critical (the user usually does not want to wait long). Redundancy must be implemented as well, to catch up the (often) occasions of disappearing peers. Privacy is ensured, since no peer can know which word index is stored, updated or passed since word indexes are stored under a word hash, not the word itself. Search mis-use is regulated by the p2p-laws of give-and-take: every peer must contribute in the crawl/proxy-and-index - process before it is allowed to search.
|
Privacy
Sharing the index to other users may concern you about your privacy. We have made great efforts to keep and secure your privacy:
| Private Index and Index Movement |
Your local word index does not only contain information that you created by surfing the internet, but also entries from other peers.
Word index files travel along the proxy peers to form a distributed hash table. Therefore nobody can argue that information that
is provided by your peer was also retrieved by your peer and therefore by your personal use of the internet. In fact it is very unlikely that
information that can be found on your peer was created by you, since the search process targets only peers where it is likely because
of the movement of the index to form the distributed hash table. During a test phase, all word indexes on your peer will be accessible.
The future production release will constraint searches to indexes entries on your peer that have been created by other peers, which will
ensure complete browsing privacy.
| | Word Index Storage and Content Responsibility |
The words that are stored in your local word index are stored using a word hash. That means that not any word is stored, but only the word hash.
You cannot find any word that is indexed as clear text. You can also not re-translate the word hashes into the original word. This means that
you don't know actually which words are stored in your system. The positive effect is, that you cannot be responsible for the words that
are stored in your peer. But if you want to deny storage of specific words, you can put them into the 'bluelist' (in the file yacy.bluelist).
No word that is in the bluelist can be stored, searched or even viewed through the proxy.
| | Peer Communication Encryption |
Information that is passed from one peer to another is encoded. That means that no information like search words,
indexed URL's or URL descriptions is transported in clear text. Network sniffers cannot see the content that is exchanged.
We also implemented an encryption method, where a temporary key, created by the requesting peer is used to encrypt the response
(not yet active in test release, but non-ascii/base64 - encoding is in place).
| | Access Restrictions |
The proxy contains a two-stage access control: IP filter check and an account/password gateway that can be configured to access the proxy.
The default setting denies access to your proxy from the internet, but allowes usage from the intranet. The proxy and it's security settings
can be configured using the built-in web server for service pages; the access to this service pages itself can also be restricted again by using
an IP filter and an account/password combination.
|
|
